
Data Diversification: An Elegant Strategy For Neural Machine Translation
Published in 34th Conference on Neural Information Processing Systems (NeurIPS 2020), Vancouver, Canada, 2020
Recommended citation: Xuan-Phi Nguyen, Shafiq Joty, Wu Kui, & Ai Ti Aw (2019). Data Diversification: An Elegant Strategy For Neural Machine Translation. In the 34th Conference on Neural Information Processing Systems (NeurIPS 2020), Vancouver, Canada, 2020.
Paper Link: https://arxiv.org/abs/1911.01986
Abstract
We introduce Data Diversification: a simple strategy to boost neural machine translation (NMT) performance. It diversifies the training data by using the predictions of multiple forward and backward models and then merging them with the original dataset on which the final NMT model is trained. Our method is applicable to all NMT models. It does not require extra monolingual data like back-translation, nor does it add more computations and parameters like ensembles of models. In the experiments, our method achieves state-of-the-art BLEU score of 30.7 & 43.7 in the WMT'14 English-German & English-French tasks. It also substantially improves on 8 other translation tasks: 4 IWSLT tasks (English-German and English-French) and 4 low-resource translation tasks (English-Nepali and English-Sinhala). We demonstrate that our method is more effective than knowledge distillation and dual learning, it exhibits strong correlation with ensembles of models, and it trades perplexity off for better BLEU score. We have released our source code at this URL.
Summary
Data Diversification strategy trains the models in $N$ rounds. In the first round, we train $k$ forward models $(M^1_{S \rightarrow T,1},...,M^k_{S \rightarrow T,1})$ and $k$ backward models $(M^1_{T \rightarrow S,1},..,M^k_{T \rightarrow S,1})$, where $k$ denotes a diversification factor. Then, we use the forward models to translate the source-side corpus $S$ of the original data to generate synthetic training data. In other words, we obtain multiple synthetic target-side corpora as $(M^1_{S \rightarrow T,1}(S),...,M^k_{S \rightarrow T,1}(S))$. Likewise, the backward models are used to translate the target-side original corpus $T$ to synthetic source-side corpora as $(M^1_{T \rightarrow S,1}(T),...,M^k_{T \rightarrow S,1}(T))$. After that, we augment the original data with the newly generated synthetic data, which is summed up to the new round-1 data $\mathbf{D}_1$ as follows: \begin{equation} \mathbf{D}_1 = (S,T) \bigcup \cup_{i=1}^k (S, M^i_{S \rightarrow T,1}(S)) \bigcup \cup_{i=1}^k (M^i_{T \rightarrow S,1}(T), T) \end{equation} After that, process continues for round 2. The following algorithm summarize the method.

Experiments
We compare our method against the state of the art Scale Transformer and Dynamic Convolution in the WMT'14 English-German and English-French translation tasks. As shown in the table below, our method outperform the baselines around 1 BLEU. In comparison with other supporting techniques, such as Knowledge Distillation or Multi-agent Dual Learning, our method also shows superior performance.
Plus, we tested our method on smaller scale IWSLT'14 English-German and IWSLT'13 English-French tasks. Our method also shows significant improvements.
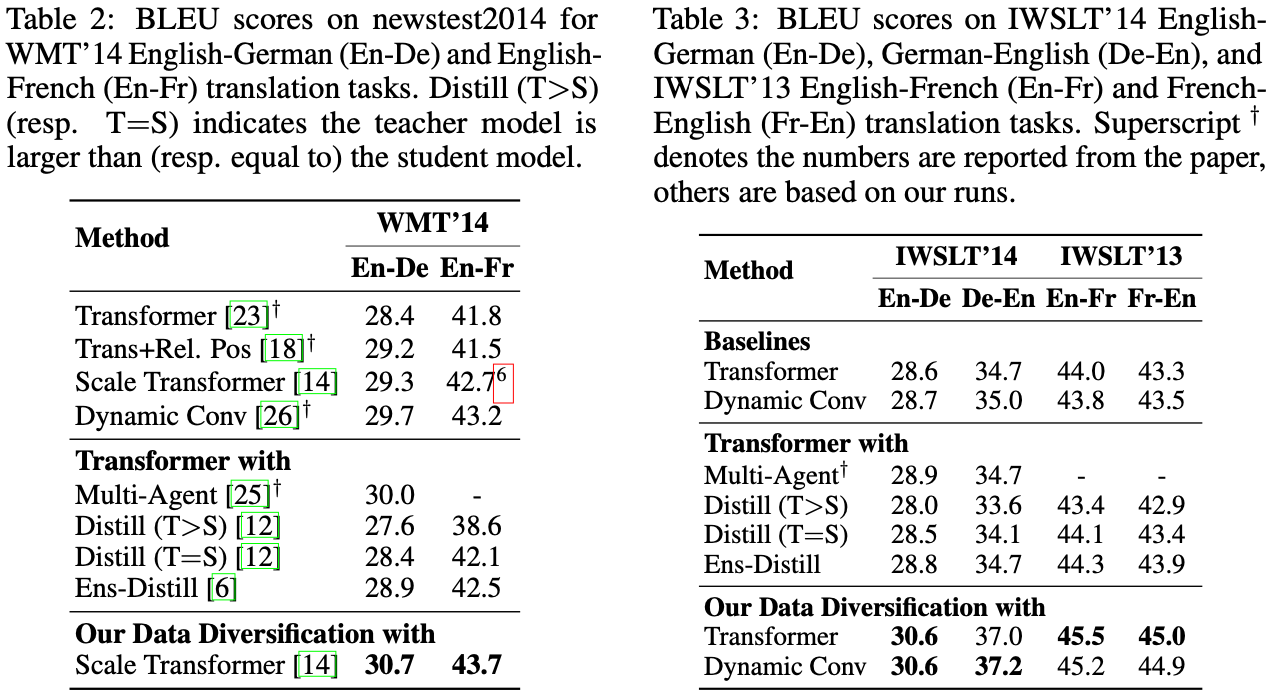
In addition, our method improves the translation performances of low-resource languages, such as Nepali and Sinhala.
Understanding Data Diversification
We conducted a series of experiments and analyses to find out how and why data diversification works well despite being very simple. In the following, we summarize our findings and conclusions with further experiments.
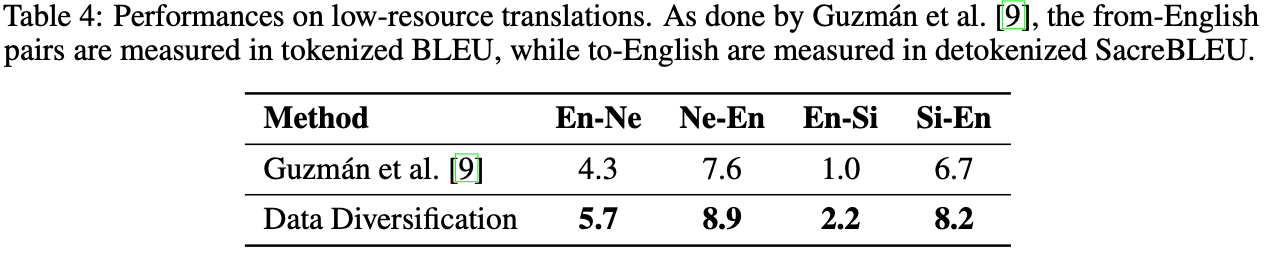
- Data diversification exhibits a strong correlation with ensemble of models. The table below show the performance comparison, while we explain further mathematically in the paper.
- Forward translation is crucial to the performance gain, which is in contrast to the common belief that back-translation is more important.
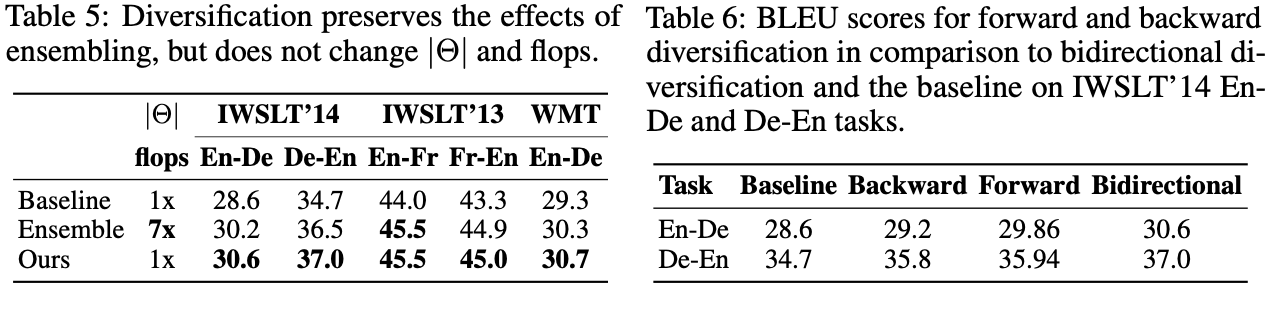
- Data diversification sacrifices perplexity for better BLEU score. As shown in the table below, our method increases perplexity (PPL) but also improves the BLEU performance.
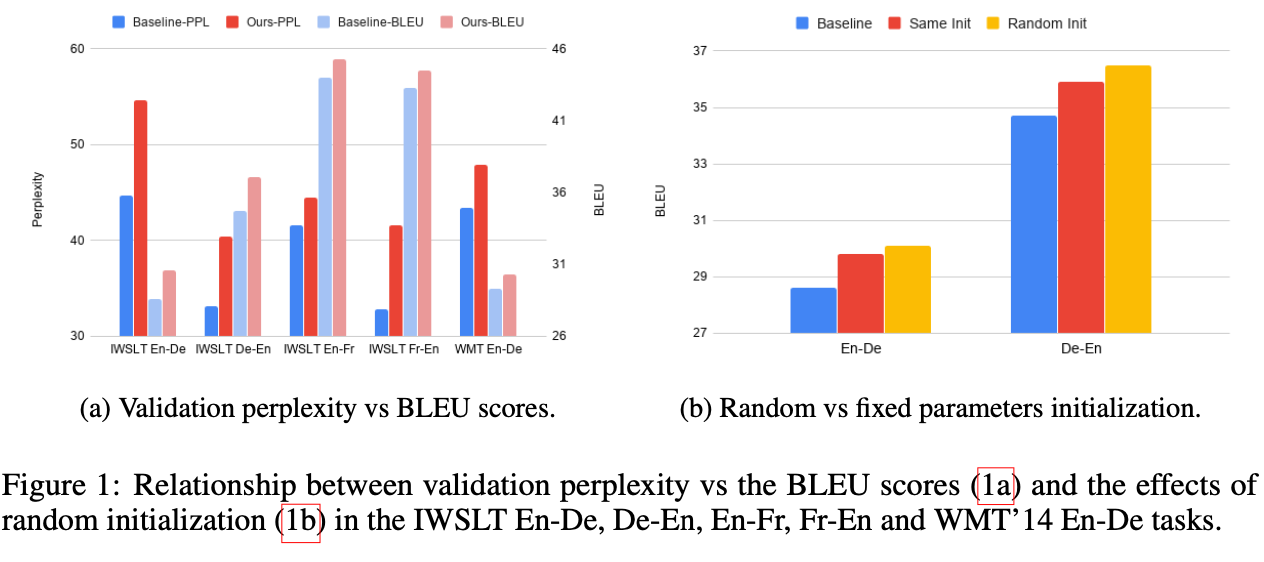
- Randomization of initial parameters of multiple models are vital to the diversity of synthetic, hence the final performance.
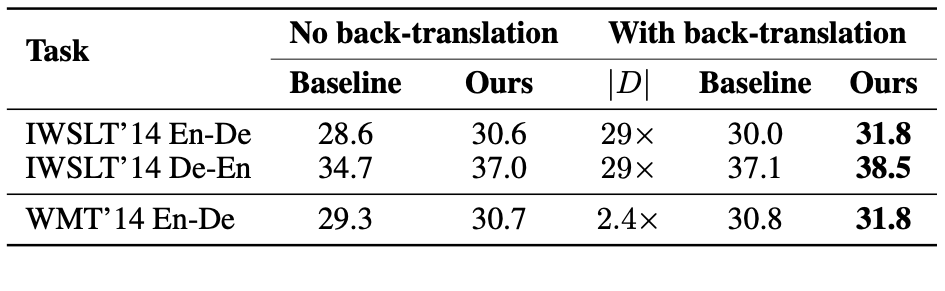
Complementary to Back-translation in Semi-supervised setup
We found that our method further improves back-translation.
Ablation Study
Our ablation study shows that increasing the number of rounds $N$ does not significant improvement. However, increasing factor $k$ drastically improves the performance but we observe diminishing return.
