Cross-model Back-translated Distillation for Unsupervised Machine Translation
Published in 38th International Conference on Machine Learning (ICML), 2021
Recommended citation: Xuan-Phi Nguyen, Shafiq Joty, Thanh-Tung Nguyen, Wu Kui, & Ai Ti Aw (2021). Cross-model Back-translated Distillation for Unsupervised Machine Translation. In Proceedings of the 38th International Conference on Machine Learning (ICML 2021).
Paper Link: https://arxiv.org/abs/2006.02163
Abstract
Recent unsupervised machine translation (UMT) systems usually employ three main principles: initialization, language modeling and iterative back-translation, though they may apply these principles differently. This work introduces another component to this framework: Multi-Agent Cross-translated Diversification (MACD). The method trains multiple UMT agents and then translates monolingual data back and forth using non-duplicative agents to acquire synthetic parallel data for supervised MT. MACD is applicable to all previous UMT approaches. In our experiments, the technique boosts the performance for some commonly used UMT methods by 1.5-2.0 BLEU. In particular, in WMT'14 English-French, WMT'16 German-English and English-Romanian, MACD outperforms cross-lingual masked language model pretraining by 2.3, 2.2 and 1.6 BLEU, respectively. It also yields 1.5-3.3 BLEU improvements in IWSLT English-French and English-German translation tasks. Through extensive experimental analyses, we show that MACD is effective because it embraces data diversity while other similar variants do not.
Summary
Recent state-of-the-art unsupervised machine translation (UMT) systems usually employ three main principles: initialization, language modeling and iterative back-translation, though they may apply these principles differently. This paper introduces a new add-on to the three-principle UMT framework: Multi-Agent Cross-Translated Diversification (MACD). The technique is applicable to any existing UMT methods and is shown in this paper to significantly improve the performance of the underlying UMT method.
As simple as it may sound, The procedure first trains multiple UMT agents (models), then each of them translates the monolingual data from one language $X$ to another $Y$ in the first level. After that, in the second level, the generated data are again translated from language $Y$ back to $X$ by agents other than the one of its origin to produce level 2 synthetic data - a process which we call cross-translation. The process continues until the $k$-th level. In the final step, a supervised MT model is trained on all those synthetic parallel data.
Multi-agent cross-translated diversification (MACD)
Let $S$ and $T$ be the sets of monolingual data for languages $s$ and $t$, respectively. We first train $n$ UMT agents $M_1,M_2,...,M_n$, where $n$ is called the diversification multiplier. The agents can be implemented following any of the existing UMT techniques. They are trained independently and randomly such that no two agents are the same or guaranteed to generate the same output for any given input. Since the models are bidirectional, we denote $M_i^{s\rightarrow t}(X_s)=Y$ to be the translations from language $s$ to $t$ of corpus $X_s$ (of language $s$) by UMT agent $M_i$, and vice versa for $M_i^{t\rightarrow s}(X_t)=Y$.
The MACD procedure is then summarized in the following algorithm.

Experiments
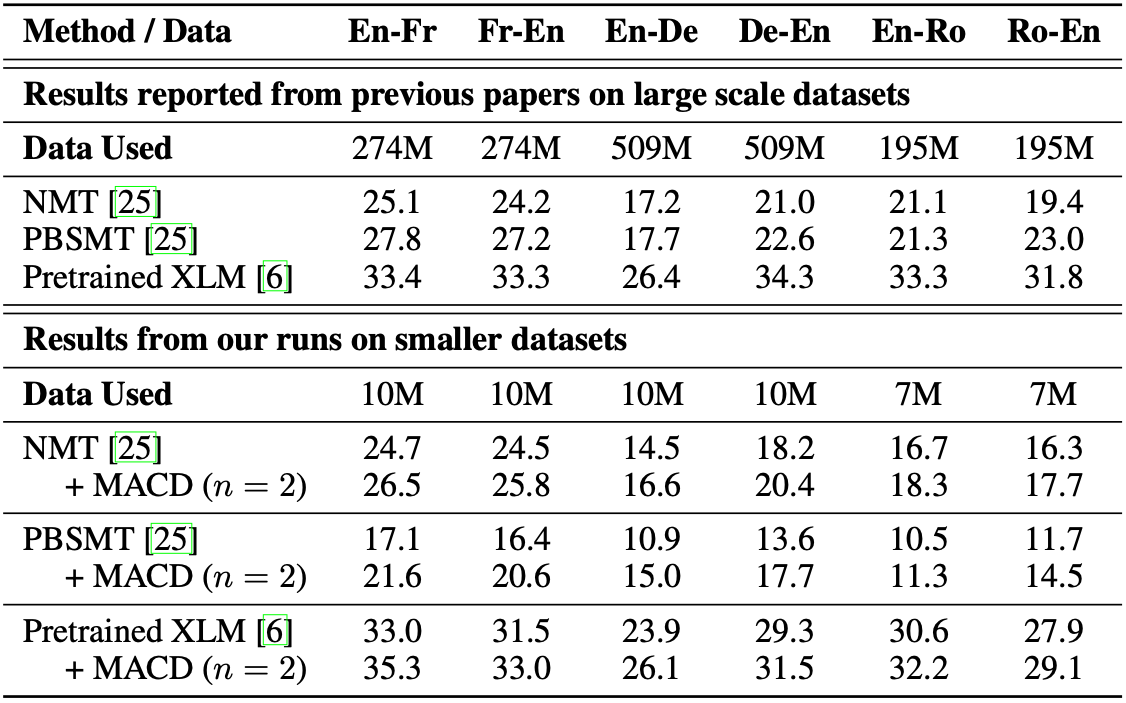
We compare our method with common baselines: NMT & PBSMT and Pretrained XLM. However, we were unable to replicate the exact enormous scale setup in those papers, which use the News Crawl 2007-2017 datasets. Instead, we reproduce their results using the smaller News Crawl 2007-2008 datasets.
The WMT results are shown as follow. Our method generally improve the performance of the underlying baseline by 2-3 BLEU.
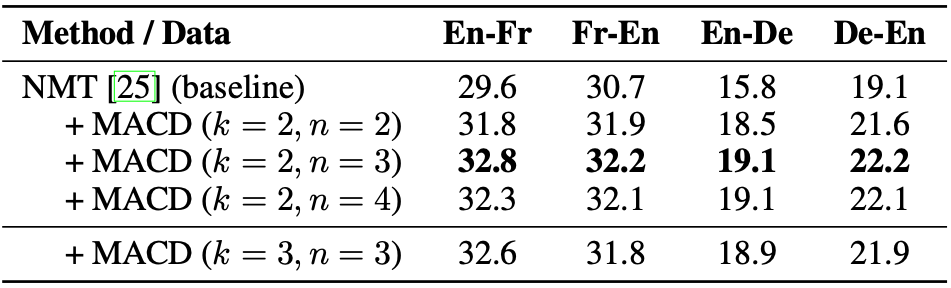
For IWSLT datasets, we test different variants of MACD against the baseline in the IWSLT'14 De-En and IWSLT'13 En-Fr tasks.
Understanding MACD
To understand MACD, we run a series of analysis experiments and found that cross-translation plays a vital role in the improvement of MACD. Indeed, we tried different variants of methods that use multiple agents without cross-translation (MADs) and show that they does not improve the baseline performance.
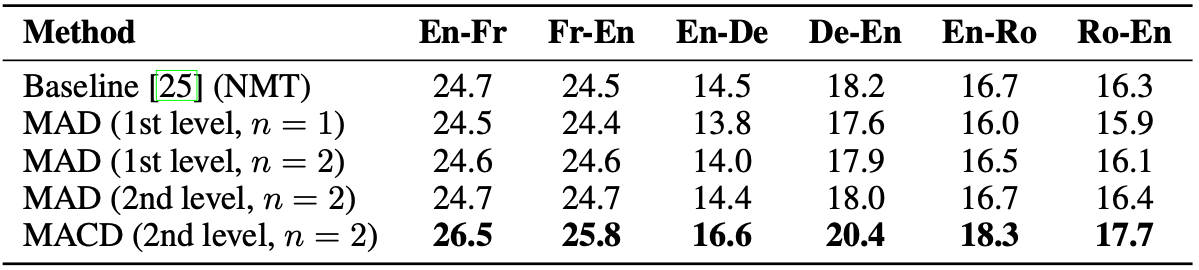
Further analyses show that MACD produces hightly diverse data compared to other variants. We compute the reconstruction BLEU scores of the back-translation process of MACD and MAD and observe that the score for MACD is much lower than MAD's, indicating that the generated data is highly distinct from the originals. Plus, Across the language pairs, only around 14% of the parallel data are duplicates. Given that 87.5% of the data are not real, this amount of duplicates is surprisingly low.


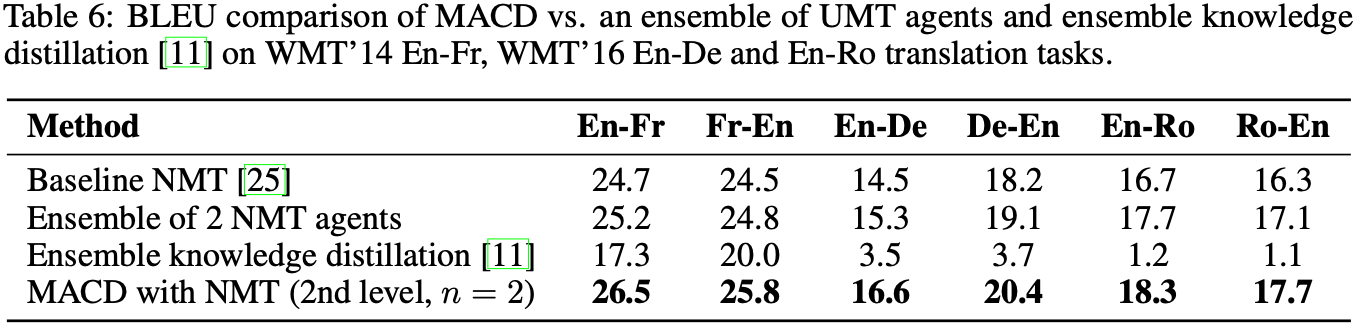
We also compare MACD with ensemble of models and found that MACD outperforms different ensembling approaches, including Ensemble knowledge distillation.